Introducción a la Programación Paralela
Índice
Se necesita PP cuando:
- tenemos unos requerimientos computacionales elevados que se escapan de la potencia de cálculo que ofrecen equipos domésticos.
- queremos resolver problemas simplificados de forma más ajustada a la realidad, con mayor número de parámetros, modelos más cercanos a la realidad física del problema, etc.
- necesitamos calcular de forma más rápida: equipos domésticos pueden calcular pero no en un tiempo lo suficientemente corto como para que sea útil en ciertos ámbitos.
Aplicaciones
Aplicaciones típicas son de arquitectura en ingeniería. CFD, métodos numéricos de cualquier tipo, modelación de terremotos, sistemas electrónicas, etc.
Arquitectura
Clasificación a nivel físico
Los clúster tienen la ventaja de menor latencia por la conectividad entre los distintos nodos. Pero suelen ser para de menor tamaño.
El problema de los nodos conectados en red (no clúster) es que la latencia introducida por la red puede ser importante porque al final estamos conectando mediantes redes1.
El ordenador del CESGA que vamos a usar es un clúster.
Clasificación según memoria
La clasificación más importante para esta asignatura es entre memoria compartida y memoria distribuida.
Memoria compartida (OpenMP)
Espacio global al que pueden acceder todas las unidades de procesamiento. Todas comparten el mismo espacio de direcciones de memoria. La comunicación se realiza de forma implícita a partir de esta memoria compartida. Cada core con su propia caché. Todos los core pueden ver obviamente la memoria compartida entre todos. Cada procesador se encarga de procesar una parte de dicha memoria compartida, y cada uno debe escribir en una zona distinta para no chafarse los resultados. Más fácil de programar. Tienen que sincronizarse con semáforos, secciones críticas, barreras, etc. Es la arquitectura que tienen los equipos domésticos.
Memoria distribuidad (MPI)
En este caso todos los procesos tienen memoria local, pero no comparten memoria por lo que la comunicación es explícita a través del paso de mensajes. Se usa para clúster de computadores: redes de computadores entre las que se distribuye el trabajo a realizar. Más escalable, más complejo de programar. Más fácil de sincronizar, normalmente de forma implícita gracias al propio mensaje, que lleva qué parte ha de calcularse, etc. El programador necesita saber dónde están los datos para saber dónde están los datos que quiere pasarle a cada proceso.
Programación de Sistemas HPC
Tienen una serie de etapas:
- decomposición: partir computación en tareas pequeñas que se distribuyen entre los procesadores, balanceando la carga. Es importante tenerlo en cuenta porque sino podemos encontrarnos en la situación en que un proceso realice casi todo el trabajo, por lo que la mejora de aplicar programación parelela en ese caso será prácticamente nula, sino negativa. Hay algoritmos en que es complicado y que hay que asignar carga de forma dinámica porque inicialmente no somos capaces de asignar trabajo por igual, como por ejemplo en búsqueda en profundidad en grafos.
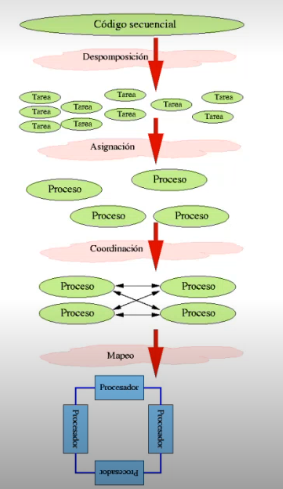
- asignación: asignar a procesos/hilos (estático vs dinámico) 2.
- coordinación: sincronización o comunicación en función del tipo de programación paralela que estemos aplicando.
mapeo: decidir cómo se ejecuta el código en cada procesador. Normalmente 1:1
Es importante enfocarse en la parte de mayor coste computacional (hot spots).
Programación de Memoria Compartida
Normalmente basado en threads, usando modelo fork-join. Podemos usar directamente hilos, como por ejemplo pthreads, pero OpenMP nos simplifica esto.
OpenMP
Lenguaje de más alto nivel que usar directamente hilos, interfaz para Fortran y C/C++. Se compone de directivas que se colocan en ciertos puntos del código secuencial, y el compilador se encarga de crear toda la magia de forma transparente para el programador, creando threads, sincronizando, etc. Es un estándard portable, el más usado en HPC cuando se usa memoria compartida.
Podemos programar en nuestro ordenador y subir a finisterrae una vez implementado y probado en local.
Permite paralelismo a varios niveles.
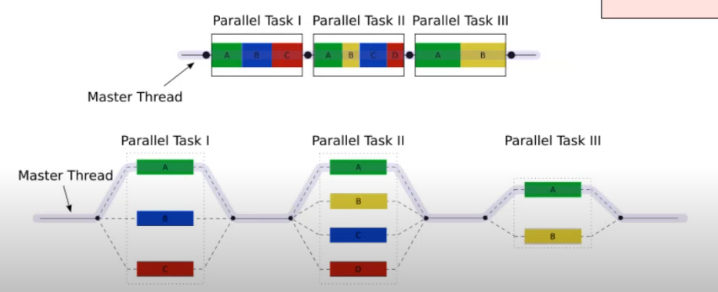
Paralelismo a nivel tarea
Podemos dividir y luego esperar a que se termine todo el código. Como lanzar hilos y al final hacer un join a todos los cálculos que hemos empezado previamente esperando hasta que terminen de ejecutarse todos.
OpenMP ejemplo a nivel de tarea
{kind=link}
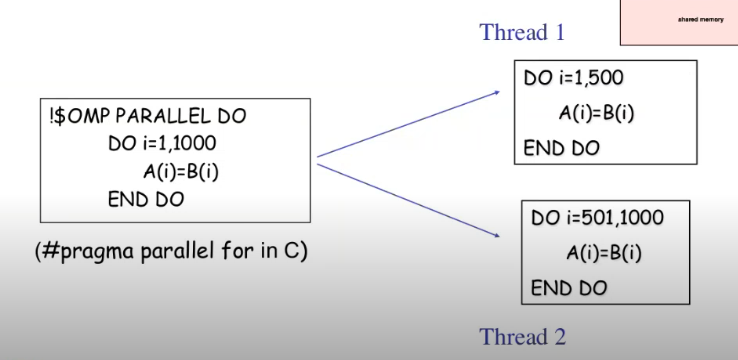
Paralelismo a nivel de loop
Muy típico, se pone la directiva encima de la definición de un bucle.
OpenMP ejemplo a nivel de loop
{kind=link}
gcc y gfortran puede compilar OpenMP, no necesitamos compildores privativos como puedan ser los de Intel, IBM, HP, etc.
No hay muchas librerías que estén preparadas para usar OpenMP, y toca programarse muchas cosas que podríamos pensar que hay código ya preparado para ello. Intel MKL tiene soporte, pero es privada.3
Otros
Hay otras tecnologías como Cilk, Intel TBB…
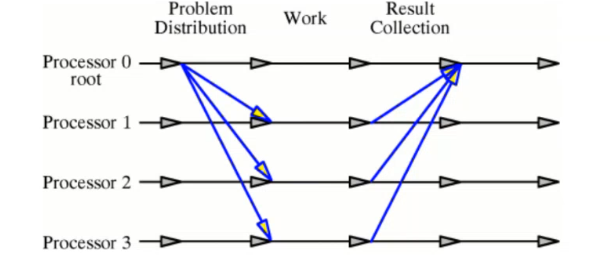
Programación con memoria distribuida
Procesadores que se comunican mediante mensajes. Esquema memoria distribuida - paso de mensajes
{kind=link}
El programador debe distribuir los datos que quiere procesar entre los nodos de forma explícita.
MPI
El estándard para memoria distribuida. Para C/C++ y Fortran. Más bajo nivel que OpenMP y más complidado. Existen interfaces para Java y Python pero no son estándares. Son proyectos personales, etc. Por esta razón es más flexible, y se pueden crear modificaciones para ajustarse mejor a ciertas arquitecturas.
La librería recomendada a usar es OpenMPI.
Programar con MPI es bastante tediosos, pero hay bastantes librerías paralelas para aplicaciones científicas / ingenieriles que podemos usar. Exige escribir bastante más código que OpenMP. Pero es mucho más flexible.
La comunicación entre procesos se realiza mediante funciones.
- punto -> punto :
MPI_Send(...)yMPI_Recv(...) - colectivo :
MPI-Bcast(...)para fan-out, /MPI_Scatter(...)yMPI_Gather(...)para algo más complejo. Scatter es 1->M y sirve para distribuir los cálculos, Gather es M->1 y sirve para recolectar resultados.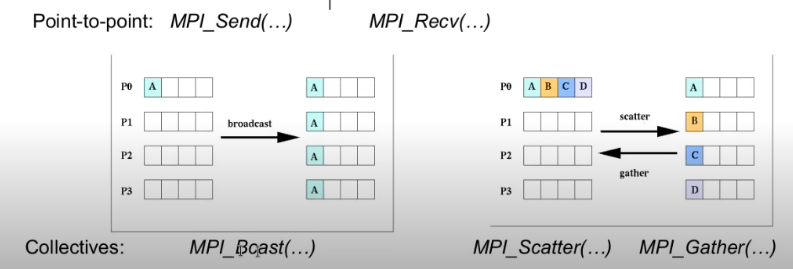
Sistemas híbridos
Podemos tener sistemas híbridos con MPI y OpenMP trabajando juntos: un proceso es un 1 nodo de MPI y cada uno lanza varios hilos que se paralelizan con OpenMP.
Notas
Obviamente no es lo mismo red que conecte equipos en la misma habitación con anchos de banda de GB/s que redes de ordenadores ubicados en distintos países y conectados a través de internet.
Se ve en PPA (Programación Paralela Avanzada)
La usada por numpy si no me equivoco, no sé qué condiciones de uso tiene para que se pueda usar por numpy y por todo el código privado que corre en producción con numpy.